What is the Synthetic Data Generation Market Size?
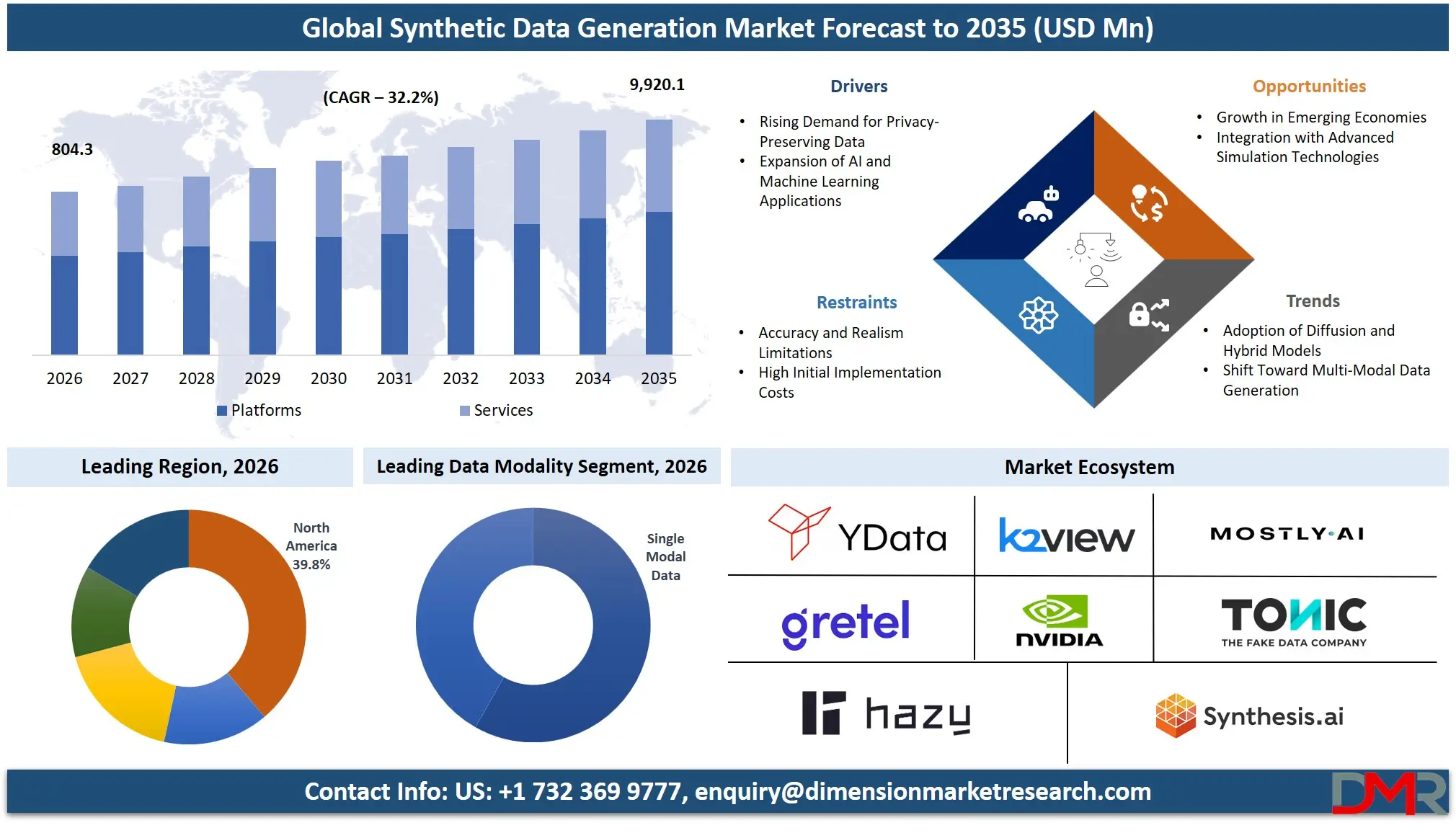
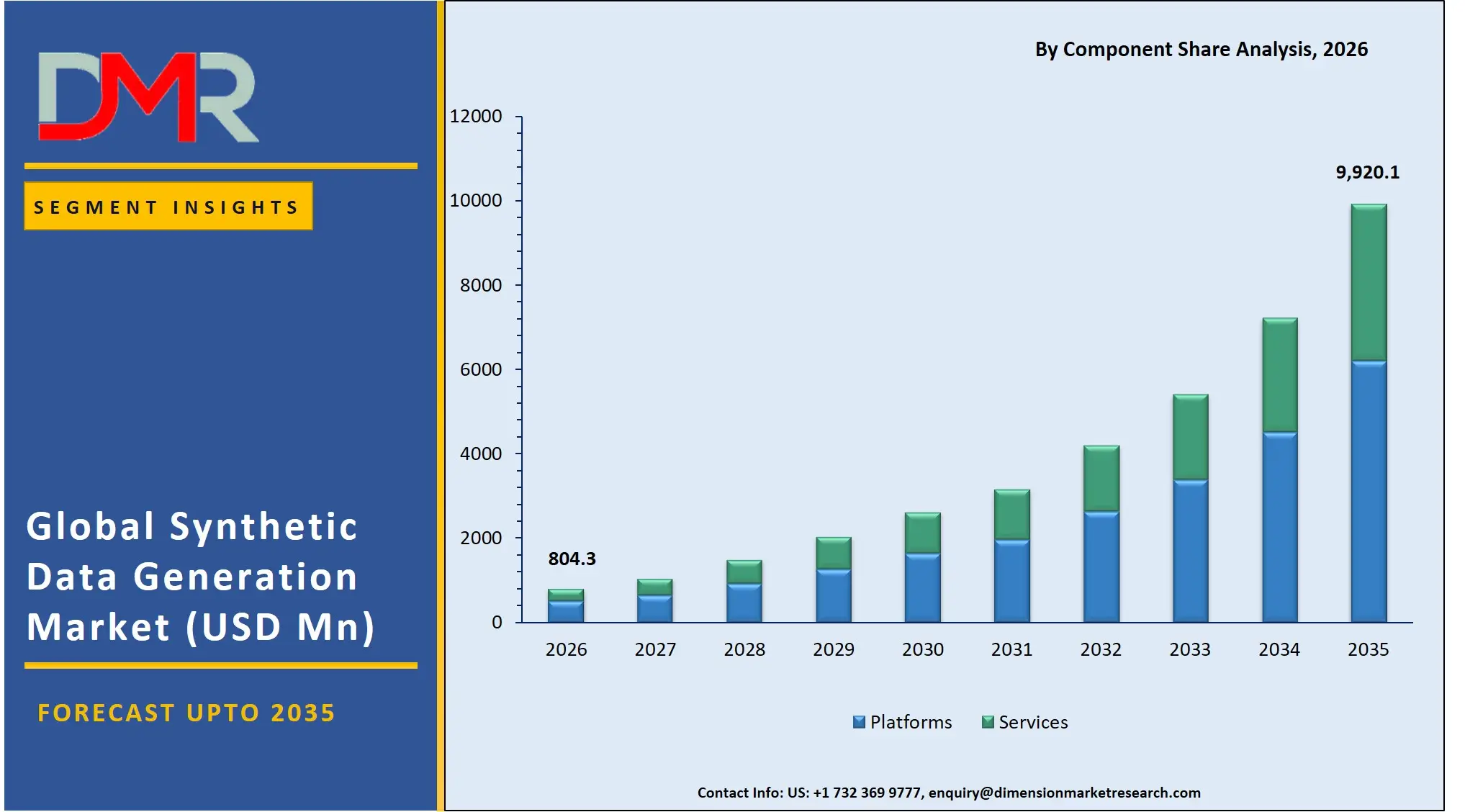
The Synthetic Data Generation Market size is expected to be USD 804.3 million in 2026 and increase at a compound annual growth rate of 32.2% to USD 9,920.1 million in 2035 due to the organizations requiring a solution that would provide them with data to analyze without facing any legal issues.
ℹ
To learn more about this report –
Download Your Free Sample Report Here
The Synthetic Data Generation Market is experiencing exponential growth as more companies are turning to synthetic data in training, testing, and validating AI models while ensuring confidentiality and minimizing costs. The market consists of platforms, tools, and services used in generating realistic data in different modalities including text, images, audio, and tabular formats.
The growth is attributed to increased adoption of AI technologies, stringent data protection laws, and the need for scalable datasets. Some of the emerging trends in the sector include diffusion models, simulation modeling techniques, and the integration of synthetic data generation in enterprise AI processes.
ℹ
To learn more about this report –
Download Your Free Sample Report Here
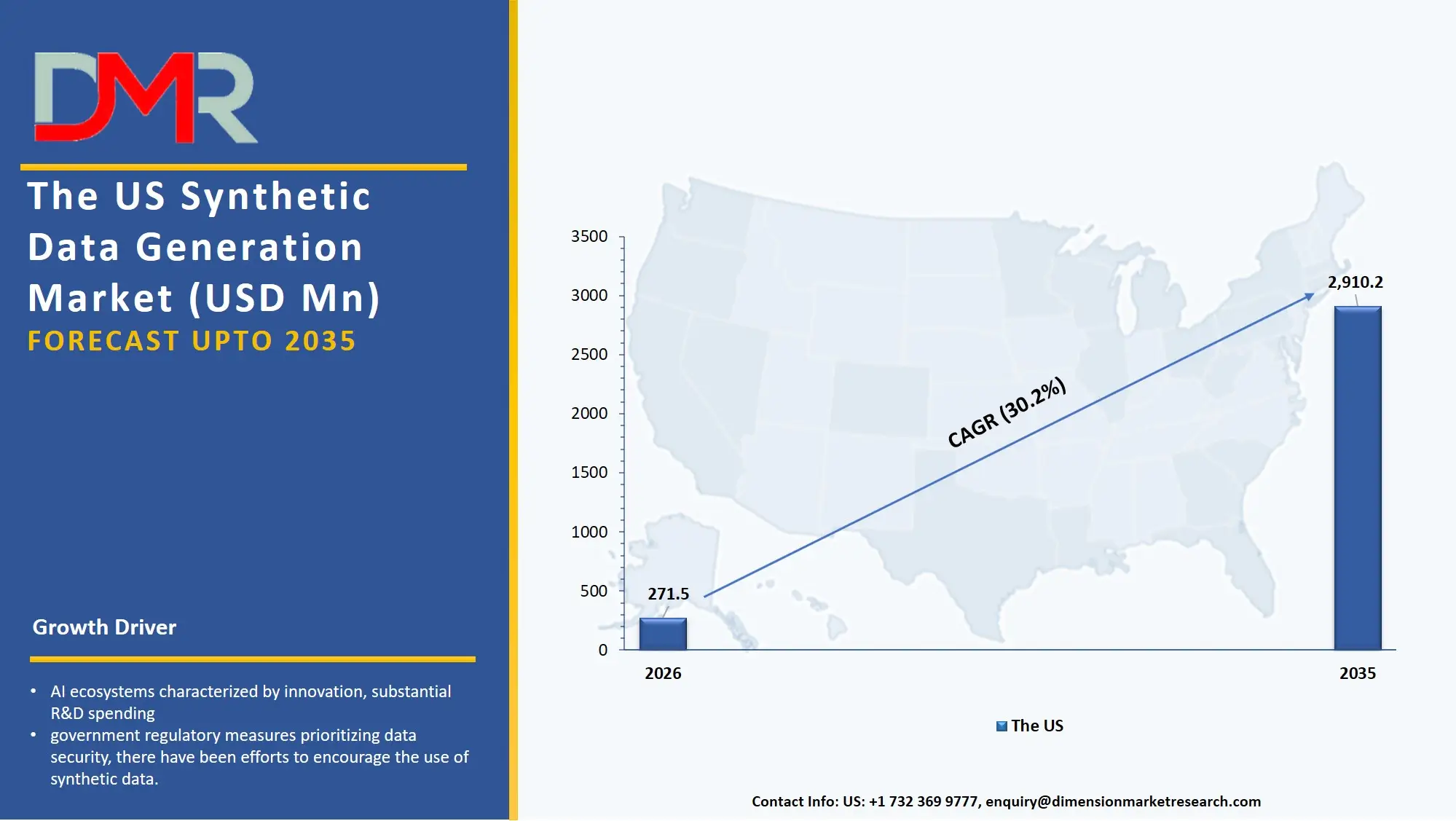
The US Synthetic Data Generation Market
The US Synthetic Data Generation Market size is estimated to be USD 271.5 million in 2026 and is expected to increase at a CAGR of 30.2% over the forecast period.
ℹ
To learn more about this report –
Download Your Free Sample Report Here
The US market has been shaped by AI ecosystems characterized by innovation, substantial R&D spending, and early adoption in industries like health care, self-driving vehicles, and defense. With government regulatory measures prioritizing data security, there have been efforts to encourage the use of synthetic data. Businesses in the form of large corporations and startups are increasingly adopting the use of synthetic data in AI development.
Europe Synthetic Data Generation Market
The Europe Synthetic Data Generation Market size is estimated to be USD 201.0 million in 2026 and at a CAGR of 31.3% over the forecast period.
The market in Europe is greatly impacted by the data security laws, which include GDPR, among others, as well as sustainability-oriented measures, such as the European Green Deal. This compels the organizations to opt for privacy-preserving data technologies. Such solutions are widely used within healthcare, automotive industry, and public sector projects. Innovative research is done through collaboration, and businesses are focusing on ethical AI methods, which makes synthetic data particularly important.
Japan Synthetic Data Generation Market
The market size of Japan Synthetic Data Generation will be USD 32.2 million in 2026 and at a CAGR of 31.5% in the forecast period.
Market growth in Japan relies on the country's sophisticated industrial framework, expertise in robotics, and government support for artificial intelligence innovations. Some industries that stand out in this regard include the auto industry, manufacturing industry, and smart city developments. Urbanization and digitalization are increasing the need for datasets that can be scaled up. At the same time, some barriers exist, including traditional attitudes towards adopting new technologies.
Key Takeaways
- Market Size & Forecast: The Synthetic Data Generation Market size is projected to reach USD 804.3 million in 2026 and is anticipated to have a value of USD 9,920.1 million in 2035.
- Growth Rate & Outlook: The Synthetic Data Generation Market size is set to grow at a compound annual growth rate of 32.2% during the forecast period of 2026 to 2035.
- Primary Growth Drivers: Some of the major growth drivers in the market include Increasing Requirement for Privacy-Preserved Data, and more.
- Key Market Trends: Some of the major trends in the market are Adoption of Diffusion and Hybrid Models, and more.
- By Component: The platforms segment is anticipated to get the majority share of the Synthetic Data Generation market in 2026.
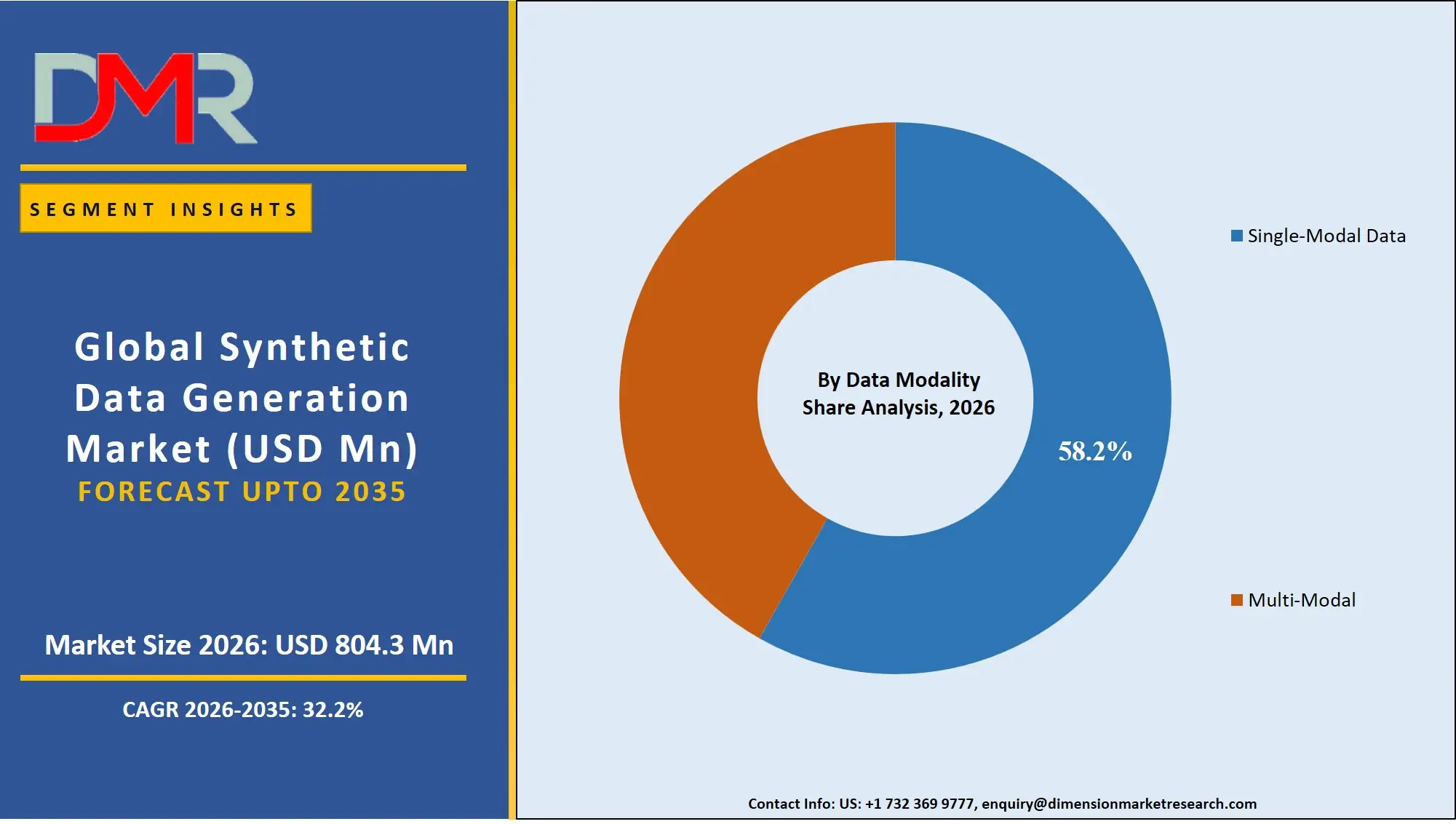
- By Data Modality: Single-Modal data segment is expected to get the largest revenue share in 2026 in the Synthetic Data Generation market.
- By Data Type: Image & video segment is expected to get the largest revenue share in 2026 in the Synthetic Data Generation market.
- Regional Leadership: North America is set to lead the Synthetic Data Generation market with an estimated 39.8% share in 2026.
What is the Synthetic Data Generation?
Synthetic data creation involves the creation of artificial datasets, similar to those in the real world through methods like algorithms, statistical models, and machine learning methods, including GANs, diffusion models, and simulation engines. These artificial datasets capture all the patterns, relationships, and structures present in real datasets without revealing any sensitive or private information. It is critical in facilitating data sharing, rapid training of AI models, enhancing testing precision, and solving challenges related to rare real-world data, among others.
Use Cases
- Machine Learning Model Training: The creation of synthetic data sets makes possible the extensive training of machine learning models when genuine data is insufficient or cannot be used due to sensitivity issues.
- Testing of Autonomous Systems: The creation of synthetic environments helps in testing autonomous systems such as cars and robots by generating edge cases, thereby ensuring their safety and reliability without any risk.
- Data Privacy and Compliance: Companies use synthetic data sets in place of genuine data sets that have privacy and compliance issues.
- Medical Research and Imaging: Synthetic data is used in medical research and imaging to avoid compromising patient privacy.
How AI Is Transforming the Synthetic Data Generation Market?
The role of AI is crucial when generating synthetic data. Thanks to the sophisticated technology, synthetic datasets can be made similar to those from the actual world. AI enhances the performance of the generated data, making it scalable, diverse, and precise enough for such applications as self-driving cars, detecting frauds, and analyzing people's health issues.
Additionally, the importance of AI lies in its capability to automate the entire process of generating data without the involvement of any human activities.
Market Dynamic
Driving Factors in the Synthetic Data Generation Market
Increasing Requirement for Privacy-Preserved Data
Data privacy has been a rising worry for organizations and individuals around the world; hence, the increased adoption of synthetic data can be attributed to this fact. Organizations require a solution that would provide them with data to analyze without facing any legal issues; thus, synthetic data provides such benefits.
Restraints in the Synthetic Data Generation Market
High Costs Involved In Implementation
Creating and implementing any type of artificial data solution involves a considerable amount of costs in terms of infrastructure and technical expertise. Small companies may have problems with adopting this technology because of its high costs.
Opportunities in the Synthetic Data Generation Market
Synthesis with Advanced Simulation Tools
The combination of synthetic data and advanced simulations is creating a lot of possibilities, especially for the automotive and defense industries. Advanced simulations are capable of creating very realistic data sets, which improve performance as well as create new paths for innovation.
Trends in the Synthetic Data Generation Market
Adoption of Diffusion and Hybrid Models
There has been increased adoption of advanced generative methods like diffusion and hybrid approaches because of their capacity to generate very realistic datasets. This technology is being applied in various sectors because it can increase the effectiveness of the generated data.
Research Scope and Analysis
The scope of the study and analysis encompasses significant segments such as components, data types, technologies, applications, industries, and modalities of data. The research also assesses market drivers and trends that will shape the future course of synthetic data development in the coming years.
ℹ
To learn more about this report –
Download Your Free Sample Report Here
By Component Analysis
Platforms hold the largest share owing to their scalability, integration potential, and capability to incorporate multiple techniques of generating synthetic data using a single tool, with an expected market valuation of about 62.4% in 2026. Businesses are gravitating toward platforms as they offer efficient orchestration of the processes involved in the production of synthetic data. This includes generating, validating, storing, and deploying AI models with data in different environments. Platforms also offer integration with cloud computing systems and MLOPs technology. In addition, services are the fastest-growing segment in the market as businesses seek customized data generation services and consulting.
By Data Type Analysis
Image & video represent the leading categories, accounting for about 34.7 percent market share in 2026, largely because of rising usage of these data in applications such as self-driving cars, medical imaging, and surveillance analysis. Image and video data have become increasingly popular because they are used to develop sophisticated computer vision algorithms in which high-quality datasets can help enhance accuracy and performance. Furthermore, industries like retail and security are making use of synthetic image and video data for simulation and analysis purposes. The fastest growing category among all is that of text data due to the fast-paced development in NLP and conversational AI technologies.
By Technology Analysis
GAN-based models are expected to capture the majority market share within the technology sector with approximately 38.9% in 2026 on account of the established capacity of generating extremely diverse and realistic data in multiple formats. The extensive adoption of these models by companies from various sectors has established them as a leading technology in the field of synthetic data generation. Nonetheless, diffusion models are predicted to be the fastest growing segment due to their enhanced performance regarding output quality, stability, and low artifacts compared to other models. These models are expected to become popular due to their capacity of producing highly accurate and detailed data. Furthermore, hybrid models are becoming increasingly popular since they offer a combination of the benefits of GAN-based, diffusion, and simulation-based models.
By Application Analysis
Training of AI/ML models is the largest application segment accounting for approximately 41.3% of the market share in 2026 due to its importance in helping organizations create accurate and scaleable machine learning models through the use of synthetic data. Synthetic data is essential in addressing challenges such as lack of data, imbalanced data sets, and data labeling expenses. This is especially vital in industries such as the health sector, financial institutions, and autonomous systems. The most promising application segment will be testing and validation due to the requirement to simulate rare or exceptional events which may not easily occur in real-world data sets.
By End Use Industry Analysis
The automotive segment has taken the lead in the end-use industry segment with a projected share of 27.6% in 2026 owing to the use of synthetic data in the development of autonomous driving and ADAS technology. Synthetic datasets help companies create simulated driving situations that include even those which may be risky and rare, thereby ensuring effective training and testing of the systems being developed. On the other hand, the healthcare segment is expected to witness high growth rates, primarily because of the rising need for datasets that comply with the issue of data privacy in research, imaging, and simulation.
By Data Modality Analysis
Single-modal data constitutes the largest segment, accounting for an estimated 58.2% share in 2026, as it continues to be prevalent in conventional uses of AI technology owing to its simplicity, ease of production, and minimal computational needs. Companies use single-modal datasets like text-only and image-only data sets for specialized purposes, making it a very viable option for focused AI programs. The most dynamic segment, however, is that of multi-modal data, which is growing steadily as a result of the rising need for sophisticated AI technologies able to comprehend and analyze various forms of data.
The Synthetic Data Generation Market Report is segmented on the basis of the following:
By Component
- Platforms
- Synthetic data platforms
- APIs & SDKs
- Services
- Consulting
- Custom data generation
- Integration & support
By Data Type
- Tabular Data
- Financial & transactional data
- Customer / CRM data
- Risk & insurance datasets
- Image & Video Data
- Autonomous driving datasets
- Medical imaging
- Surveillance & retail imagery
- Text Data
- NLP training datasets
- Chatbot / conversational AI data
- Document generation
- Audio Data
- Speech recognition
- Voice synthesis
- Call center analytics
- Time-Series Data
- IoT & sensor data
- Financial time-series
- Patient monitoring data
By Technology
- GAN-Based Models
- Image / video GANs
- Conditional GANs
- Diffusion Models
- Image generation
- Multi-modal generation
- Variational Autoencoders (VAEs)
- Simulation-Based Models
- Physics-based simulation
- Scenario-based modeling
- Hybrid Models
- GAN + simulation
- Diffusion + structured data
By Application
- AI/ML Model Training
- Computer vision
- NLP
- Speech AI
- Testing & Validation
- Autonomous systems testing
- Software testing
- Data Augmentation
- Dataset expansion
- Edge-case generation
- Data Privacy & Compliance
- Data anonymization
- Synthetic data replacement
By End-Use Industry
- Healthcare & Life Sciences
- Medical imaging
- Clinical data simulation
- BFSI
- Fraud detection
- Risk modeling
- Automotive
- Autonomous driving
- ADAS systems
- Retail & E-commerce
- Customer analytics
- Personalization
- IT & Telecom
- Network optimization
- Cybersecurity
- Government & Defense
- Surveillance
- Smart city simulation
By Data Modality
- Single-Modal
- Text-only
- Image-only
- Tabular-only
- Multi-Modal
- Image + text
- Video + sensor data
Regional Analysis
Leading Region in the Synthetic Data Generation Market
North America commands the largest market share with 39.8% for the year 2026 for synthetic data generation. The prime reason behind the leadership of North America in this industry can be attributed to the presence of a well-established artificial intelligence ecosystem along with heavy investments in R&D. Early adoption of advanced technology in fields such as health care, automobiles, and defense has further fueled the growth of the market. Strict policies related to data security, in conjunction with increasing significance of data protection, are driving the demand.
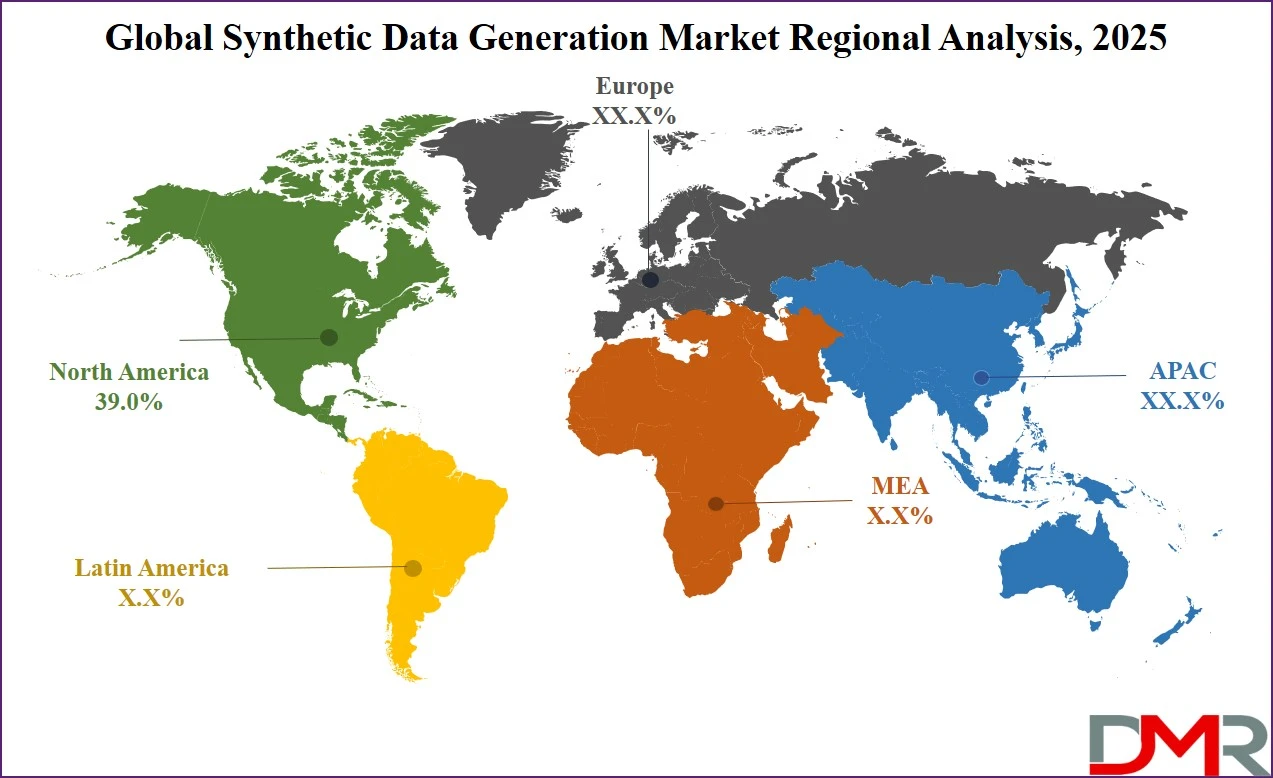
ℹ
To learn more about this report –
Download Your Free Sample Report Here
Fastest Growing Region in the Synthetic Data Generation Market
Asia Pacific is the fastest growing market for synthetic data because of rapid digital transformation, the use of AI and favorable policies from countries such as China, India, and Japan. There have been numerous investments towards creating smart cities, industrial automation, and other technology-based sectors. In addition, the rise of start-ups and data management requirements have been one of the major reasons behind the rise of synthetic data.
By Region
North America
Europe
- Germany
- The U.K.
- France
- Italy
- Russia
- Spain
- Benelux
- Nordic
- Rest of Europe
Asia-Pacific
- China
- Japan
- South Korea
- India
- ANZ
- ASEAN
- Rest of Asia-Pacific
Latin America
- Brazil
- Mexico
- Argentina
- Colombia
- Rest of Latin America
Middle East & Africa
- Saudi Arabia
- UAE
- South Africa
- Israel
- Egypt
- Rest of MEA
Competitive Landscape
The market for synthetic data creation is very competitive and is marked by innovation, technological progress, and changing consumer demands. Market players are concentrating on making their data realistic, incorporating multimodal aspects, and aligning their products with AI and cloud technologies to gain a competitive edge. There are high entry barriers owing to the requirement of niche skills and knowledge, as well as large investments in research and development. Strategic alliances and mergers and acquisitions have been adopted to increase capabilities and geographic presence and retain competitiveness based on performance and compliance.
Some of the prominent players in the global Synthetic Data Generation are:
- NVIDIA
- K2view
- Gretel.ai
- MOSTLY AI
- Tonic.ai
- Synthesis AI
- DataGen
- Hazy
- YData
- Statice
- MDClone
- Syntho
- Anyverse
- Neuromation
- Informatica
- Truata
- GenRocket
- Delphix
- Datagen Technologies
- Twenty Million Neurons
- Other Key Players
Recent Developments
- In March 2026, The SoftBank Group Corporation introduced a data generation pipeline using its Large Telecom Model (LTM). It is an AI generative foundation model designed specifically for the telecom industry. Using the NVIDIA NeMo Safe Synthesizer, which supports differential privacy, SoftBank is able to train its models safely and efficiently without the risk of leaking any confidential network information.
- In November 2025, The Amazon Web Service's product launch, known as AWS Clean Rooms, included privacy-preserving synthesis of datasets through synthetic data generation. This has made it possible for companies to generate synthetic datasets to train ML models through regression and classification. This technology ensures that privacy is maintained while ensuring the usefulness of the data.
- In October 2025, GenRocket launched its Unstructured Data Accelerator (UDA), thus extending its platform to include the generation of documents, images, and files. Based on GenRocket's Design-Driven Data™ approach, UDA allows companies to produce unstructured data that adheres to specific rules while safeguarding the privacy of sensitive data. This development increases test coverage, simplifies validation for compliance purposes, and boosts AI and document automation processes.
Report Details
| Report Characteristics |
| Market Size (2026) |
USD 804.3 Mn |
| Forecast Value (2035) |
USD 9,902.1 Mn |
| CAGR (2026-2035) |
32.2% |
| Historical Period |
2021 – 2025 |
| Forecast Period |
2027 – 2035 |
| Base Year |
2025 |
| Estimate Year |
2026 |
| Segments Covered |
By Component, By Data Type, By Technology, By Application, By End-Use Industry, By Data Modality |
| Regional Coverage |
North America – The US and Canada; Europe – Germany, The UK, France, Russia, Spain, Italy, Benelux, Nordic, & Rest of Europe; Asia-Pacific – China, Japan, South Korea, India, ANZ, ASEAN, Rest of APAC; Latin America – Brazil, Mexico, Argentina, Colombia, Rest of Latin America; Middle East & Africa – Saudi Arabia, UAE, South Africa, Turkey, Egypt, Israel, & Rest of MEA |
Frequently Asked Questions
How big is the Synthetic Data Generation Market?
▾ The Synthetic Data Generation Market size is expected to reach USD 804.3 million by 2026 and is projected to reach USD 9,920.1 million by the end of 2035.
What factors are driving the growth of the Synthetic Data Generation Market?
▾ Increasing Utilization of Programmatic Advertising, and more are the factors driving the growth of the Synthetic Data Generation Market.
Which region held the largest share of the Synthetic Data Generation Market in 2026?
▾ North America is set to lead the Synthetic Data Generation market with an estimated 39.8% share in 2026.
Who are the key players in the Synthetic Data Generation Market?
▾ Some of the key players in the Synthetic Data Generation Market include NVIDA, Hazy, K2view and more.
What is the CAGR of the Synthetic Data Generation Market from 2026 to 2035?
▾ The market is growing at a CAGR of 32.2 percent over the forecasted period.
What are the major trends in the Synthetic Data Generation Market?
▾ Adoption of Diffusion and Hybrid Models, and more are some of the major trends in the market.
How is the Synthetic Data Generation Market segmented?
▾ The Synthetic Data Generation Market is segmented by component, data type, technology, application, end-use industry, data modality.
Which region is expected to grow the fastest in the Synthetic Data Generation Market?
▾ Asia Pacific is the fastest-growing region in the Synthetic Data Generation market during the forecast period.