Market Overview
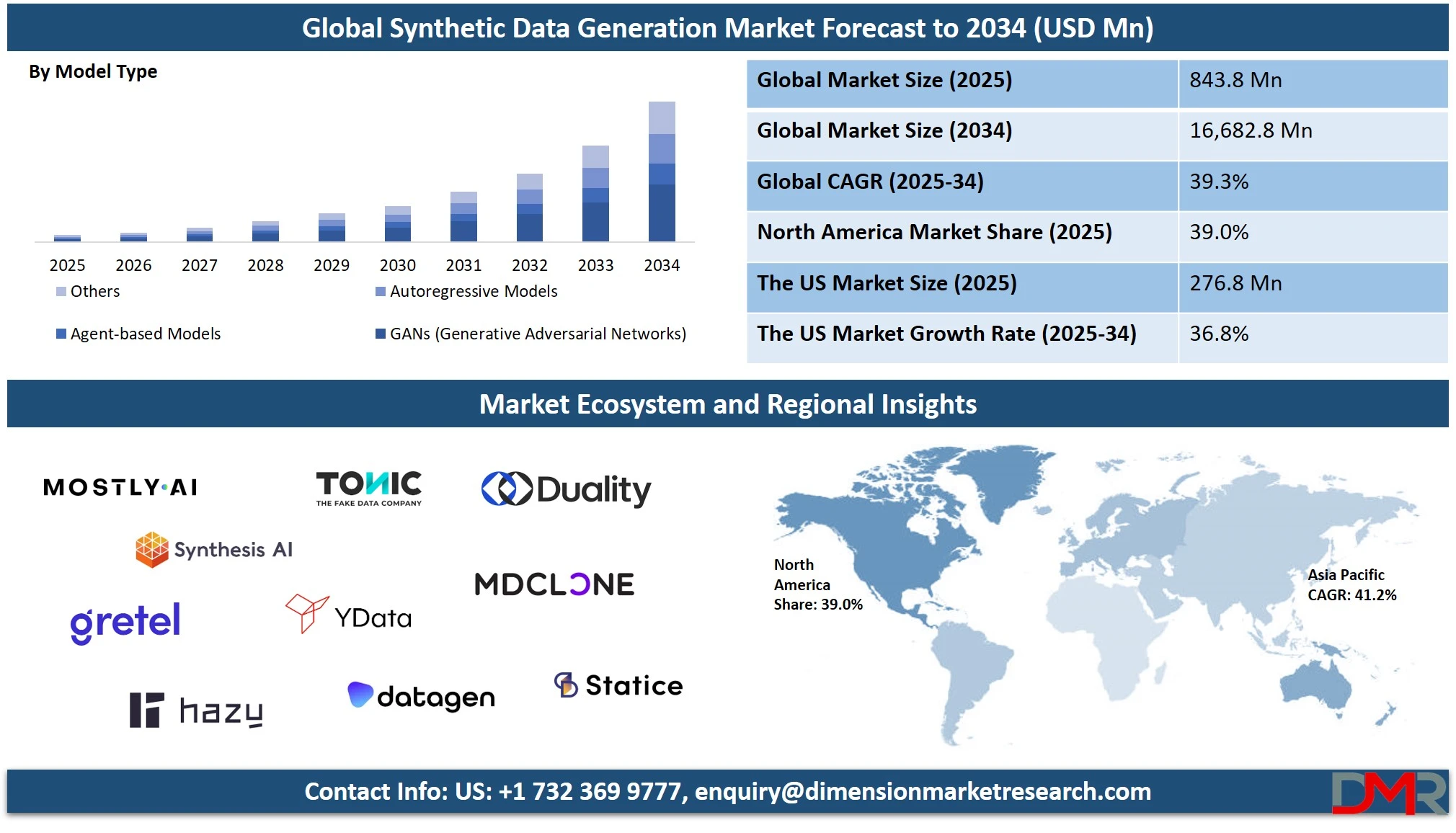
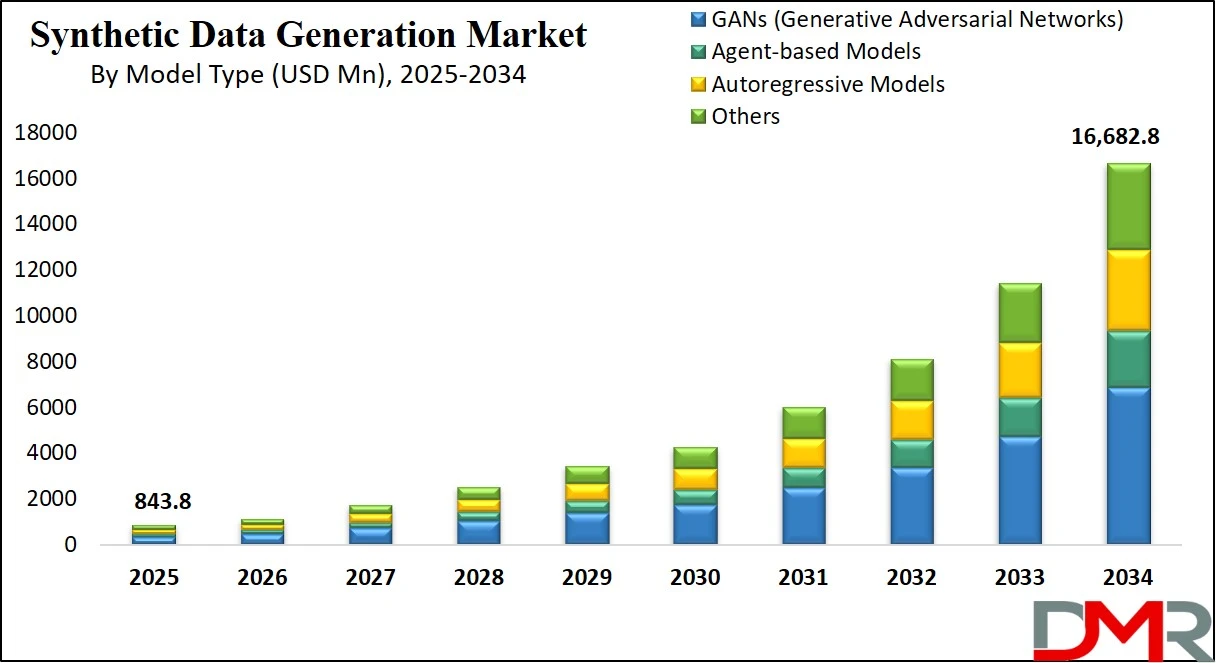
The Global Synthetic Data Generation Market is projected to reach USD 843.8 million in 2025 and is expected to grow significantly, hitting USD 16,682.8 million by 2034, expanding at a robust CAGR of 39.3%. This surge is driven by rising adoption of privacy-preserving data solutions, increased demand for AI training datasets, and the growing need for secure, scalable synthetic data platforms across industries such as healthcare, BFSI, automotive, and retail.
ℹ
To learn more about this report –
Download Your Free Sample Report Here
Synthetic data generation refers to the process of creating artificially generated data that mimics the statistical properties and structure of real-world datasets without exposing sensitive or confidential information.
It involves the use of advanced machine learning techniques such as generative adversarial networks, variational autoencoders, and other deep learning models to simulate data types like text, images, video, tabular records, and time-series streams. Synthetic data serves as a viable alternative to real data, especially in scenarios where data privacy regulations, limited data availability, or data imbalance issues hinder the use of actual datasets. It not only helps in enhancing data diversity but also supports robust AI model training, validation, and testing across various industries.
ℹ
To learn more about this report –
Download Your Free Sample Report Here
The global synthetic data generation market is witnessing significant momentum as organizations seek privacy-preserving solutions to fuel data-driven innovation. The growing demand for high-quality training datasets for machine learning and AI applications is one of the major driving forces behind the market expansion.
Sectors like healthcare, finance, automotive, and retail are turning to synthetic datasets to simulate real-world scenarios, overcome data scarcity, and ensure compliance with stringent regulations like GDPR and HIPAA. The adoption of cloud-based platforms and the integration of artificial intelligence with data simulation techniques are further accelerating the development and deployment of synthetic data tools across enterprises of all sizes.
In addition to addressing data privacy concerns, the synthetic data generation market is playing a pivotal role in enhancing the scalability and performance of AI systems. Synthetic datasets enable rapid prototyping and the generation of edge-case scenarios that are often underrepresented in real-world data.
This has made the technology particularly valuable in areas such as autonomous vehicle training, fraud detection, medical diagnostics, and customer behavior modeling. As digital transformation becomes a priority for global enterprises, the need for safe, scalable, and versatile data alternatives is positioning synthetic data generation as a cornerstone of modern AI infrastructure.
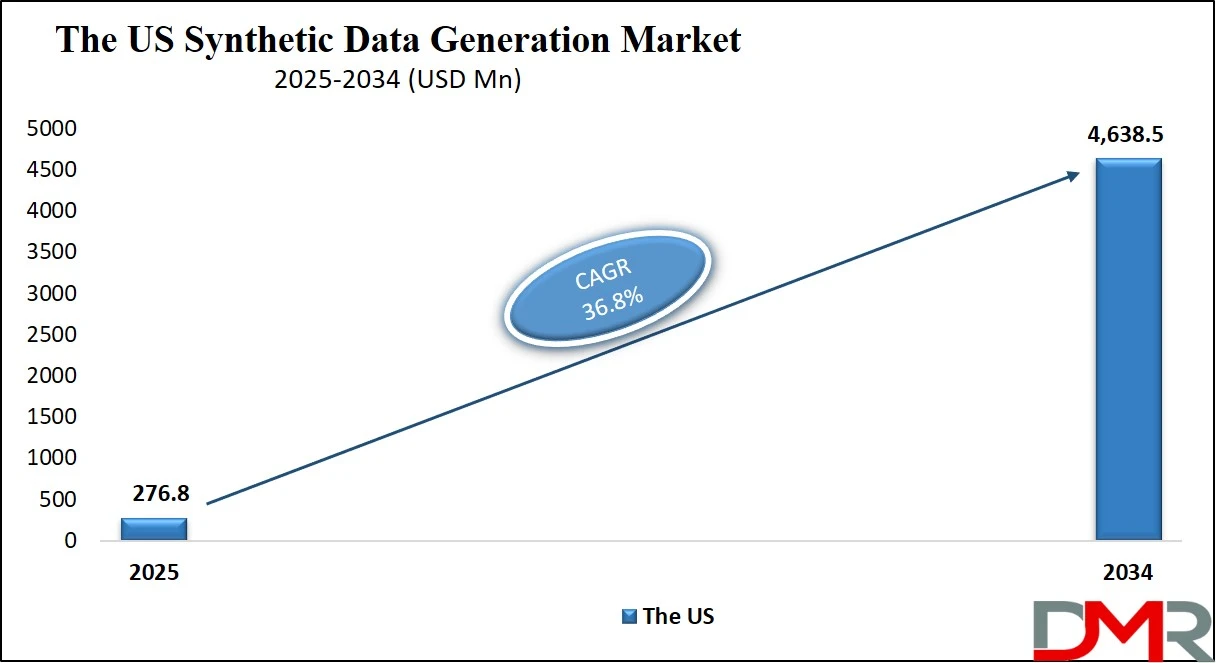
The US Synthetic Data Generation Market
The U.S. Synthetic Data Generation Market size is projected to be valued at USD 276.8 million in 2025. It is further expected to witness subsequent growth in the upcoming period, holding USD 4,638.5 million in 2034 at a CAGR of 36.8%.
ℹ
To learn more about this report –
Download Your Free Sample Report Here
The US synthetic data generation market is emerging as a global leader due to the nation’s advanced AI infrastructure, strong presence of tech giants, and growing emphasis on data privacy and security. With stringent regulations like HIPAA and growing concerns over data breaches, enterprises are turning to synthetic data solutions to safely train machine learning models while maintaining compliance.
The proliferation of cloud computing, integrated with rapid advancements in generative AI and deep learning algorithms, has enabled companies to generate large volumes of high-fidelity synthetic datasets for diverse applications such as fraud detection, medical imaging, autonomous driving, and cybersecurity simulation. Key sectors, including healthcare, BFSI, and defense, are driving adoption due to their reliance on sensitive data and the critical need to protect personally identifiable information (PII) during model development and testing.
Moreover, the US market is supported by a thriving ecosystem of synthetic data startups, government-backed AI initiatives, and a highly mature R&D environment. Major players like Google, Microsoft, IBM, and Amazon Web Services are investing heavily in synthetic data technologies, creating platforms that offer end-to-end synthetic data generation, anonymization, and validation capabilities.
The rise of smart automation, edge AI, and real-time analytics across industries is further fueling demand for scalable synthetic data frameworks. As organizations seek to overcome data scarcity, bias, and privacy constraints, the US synthetic data generation market is poised to see sustained growth, establishing itself as a cornerstone of responsible AI deployment and next-generation data engineering practices.
Europe Synthetic Data Generation Market
The Europe synthetic data generation market is estimated to be valued at USD 227.8 million in 2025. This dominance is largely driven by stringent data privacy laws such as the General Data Protection Regulation (GDPR), which encourage enterprises to adopt synthetic data as a privacy-preserving alternative to real datasets.
The region's strong presence in industries such as automotive, finance, and healthcare has further amplified demand for high-quality, bias-free, and regulation-compliant data to train machine learning models, simulate edge cases, and enhance model performance. Additionally, European AI research institutions and technology startups are playing a pivotal role in advancing synthetic data generation technologies, particularly in fields such as computer vision and natural language processing.
With a projected CAGR of 37.5% between 2025 and 2034, Europe is expected to witness substantial growth in synthetic data adoption across both public and private sectors. National AI strategies in countries like Germany, France, and the Netherlands emphasize ethical AI development and responsible data use, further accelerating demand for synthetic datasets. Emerging applications in autonomous vehicles, digital twins, and AI-driven healthcare diagnostics are opening new growth avenues.
Moreover, collaborations between European universities, startups, and large enterprises are fostering innovation in generative models such as GANs and reinforcement learning frameworks, driving Europe’s position as a leading hub for scalable and compliant synthetic data solutions.
Japan Synthetic Data Generation Market
Japan’s synthetic data generation market is projected to reach a valuation of USD 41.8 million in 2025. This growth is being fueled by Japan’s robust investment in AI technologies, particularly in areas like robotics, smart manufacturing, and autonomous systems. As the country faces challenges related to data scarcity, especially in sectors bound by strict privacy regulations such as healthcare and finance, synthetic data is emerging as a critical solution.
Japanese enterprises are leveraging synthetic datasets to support algorithm training, simulate rare scenarios, and ensure compliance without compromising sensitive real-world data. Leading companies and research institutions are also playing a vital role in adopting and developing synthetic data tools to support their AI ecosystems.
With a projected CAGR of 35.2% through 2034, Japan’s synthetic data market is poised for strong and sustained growth. This acceleration is backed by government-driven initiatives such as the Society 5.0 framework and AI strategy plans that emphasize safe, efficient data utilization in next-gen technologies.
Additionally, the growing use of synthetic data in developing AI models for autonomous vehicles, language processing, and smart city infrastructure demonstrates its expanding influence across multiple domains. As demand for privacy-preserving and bias-reducing datasets grows, Japan is expected to further integrate synthetic data technologies into its digital innovation efforts, solidifying its position as a fast-evolving player in the global synthetic data landscape.
Global Synthetic Data Generation Market: Key Takeaways
- Market Value: The global synthetic data generation market size is expected to reach a value of USD 16,682.8 million by 2034 from a base value of USD 843.8 million in 2025 at a CAGR of 39.3%.
- By Component Segment Analysis: Software components are anticipated to dominate the component segment, capturing 67.0% of the total market share in 2025.
- By Data Type Segment Analysis: Tabular Data is expected to maintain their dominance in the data type segment, capturing 39.0% of the total market share in 2025.
- By Model Type Segment Analysis: GANs (Generative Adversarial Networks) model will dominate the model type segment, capturing 41.0% of the market share in 2025.
- By Deployment Mode Segment Analysis: Cloud-Based mode is expected to consolidate its position in the deployment mode segment, capturing 71.0% of the market share in 2025.
- By Organization Size Segment Analysis: Large Enterprises are poised to consolidate their dominance in the organization size segment, capturing 66.0% of the total market share in 2025.
- By Application Segment Analysis: Data Privacy & Compliance applications will account for the maximum share in the application segment, capturing 28.0% of the total market value.
- By Industry Vertical Segment Analysis: The BFSI is expected to consolidate its dominance in the industry vertical segment, capturing 22.0% of the market share in 2025.
- Regional Analysis: North America is anticipated to lead the global synthetic data generation market landscape with 39.0% of total global market revenue in 2025.
- Key Players: Some key players in the global synthetic data generation market are Mostly AI, Synthesis AI, Gretel.ai, Hazy, Tonic.ai, YData, DataGen, Duality Technologies, Syntegra, MDClone, Statice, Delphix, Parallel Domain, Cognizant, Accenture, Microsoft, and Others.
Global Synthetic Data Generation Market: Use Cases
- Privacy-Preserving Healthcare Data for Medical AI: The healthcare industry relies on synthetic data to overcome challenges associated with patient privacy, data sharing restrictions, and limited access to diverse clinical datasets. With strict regulations such as HIPAA and GDPR, healthcare providers, pharmaceutical companies, and medical AI developers are turning to synthetic health records and medical imaging data to train and validate machine learning models. Synthetic electronic health records and diagnostic images mimic real-world data while removing any trace of identifiable patient information. This enables AI algorithms to be safely developed for disease prediction, personalized treatment planning, and drug discovery without breaching confidentiality. Moreover, synthetic datasets support the modeling of rare conditions and underrepresented patient groups, improving model accuracy and generalizability across populations.
- Autonomous Vehicle Training Using Synthetic Sensor Data: Synthetic data plays a critical role in the automotive sector, particularly in the training of autonomous vehicles and advanced driver-assistance systems. Real-world data collection from road tests is often costly, time-intensive, and limited in capturing rare or dangerous driving scenarios. By generating virtual datasets through 3D simulation environments, automotive engineers can simulate diverse driving conditions, including various weather patterns, lighting environments, and unexpected pedestrian behaviors. These synthetic sensor datasets, covering LiDAR, radar, and camera inputs, enable safer, faster, and more scalable testing of self-driving algorithms. Companies use these data to fine-tune vehicle perception systems, improve object detection accuracy, and prepare for edge-case situations that may not occur frequently in real traffic.
- Financial Fraud Detection and Risk Modeling: In financial services, synthetic data generation is transforming how institutions build and test fraud detection systems, credit scoring models, and risk assessment tools. Real transaction data is often restricted due to its sensitive nature, limiting innovation and testing. With synthetic financial datasets, banks and fintech companies can simulate a wide range of customer behaviors, fraudulent activities, and high-risk scenarios without compromising real user data. These datasets provide realistic but anonymized patterns that allow machine learning models to identify anomalies, predict financial crimes, and enhance regulatory compliance strategies such as Know Your Customer (KYC) and Anti-Money Laundering (AML) processes. The flexibility to create balanced and labeled synthetic datasets also helps address issues of data imbalance in fraud detection.
- Retail and E-commerce Customer Behavior Simulation: Retail and e-commerce platforms are leveraging synthetic data to simulate realistic customer interactions, optimize product recommendations, and enhance marketing strategies. Real consumer data often suffers from missing information, seasonal biases, or demographic imbalances. Synthetic customer profiles and transaction histories enable retailers to build more accurate AI models for demand forecasting, inventory planning, and personalized shopping experiences. These datasets help simulate new customer journeys, price sensitivity scenarios, and purchasing patterns under varying promotional strategies. By augmenting real-world data with synthetic versions, companies can improve the performance of recommendation engines and reduce model bias, ultimately leading to more data-driven decision-making across digital commerce operations.
Impact of Artificial Intelligence on Synthetic Data Generation Market
Artificial Intelligence (AI) has become the cornerstone of innovation in the synthetic data generation market, drastically enhancing the way synthetic datasets are created, validated, and deployed across industries. Traditional data generation techniques were limited in complexity and realism, often unable to replicate the nuanced patterns found in real-world data. With the integration of AI, particularly deep learning models like Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and diffusion models, the synthetic data ecosystem has evolved to produce high-fidelity datasets that are statistically accurate, context-aware, and suitable for complex AI model training.
These advanced AI algorithms enable the generation of synthetic text, images, video, tabular data, and even time-series data with precision, making them nearly indistinguishable from real data in terms of structure and utility.
The impact of AI extends beyond data creation, it also plays a crucial role in validating the quality, diversity, and bias levels of synthetic datasets. AI-driven quality assessment tools ensure that generated data maintains relevance, adheres to real-world distributions, and is free from identifiable personal information, which is essential for data privacy compliance.
Moreover, AI enables dynamic data generation at scale, allowing organizations to create customized datasets on demand for specific use cases such as fraud detection, predictive maintenance, or autonomous vehicle testing. This level of flexibility and scalability is accelerating adoption across key sectors including healthcare, BFSI, automotive, and retail. As AI continues to advance, it is expected to unlock even more sophisticated forms of synthetic data generation, including multimodal datasets and real-time synthetic data streams, solidifying its role as a critical driver in the market’s rapid growth.
Global Synthetic Data Generation Market: Stats & Facts
European Data Protection Supervisor (EDPS)
- The EDPS emphasizes that synthetic data should produce similar results to real-world datasets when subjected to the same statistical analysis.
- The authority supports synthetic data as a privacy-enhancing technique, especially under GDPR constraints, for machine learning applications in Europe.
UK Government Digital Service & Statistics Authority
- UK government guidance states synthetic data can mimic original data distributions, enabling safe data sharing and AI model development.
- Pilot projects have validated the use of synthetic datasets for education, tax, and health-related AI initiatives.
U.S. Census Bureau
- The U.S. Census Bureau uses synthetic data to allow for more granular public data release without breaching confidentiality.
- Synthetic Longitudinal Business Databases (SynLBD) replicate actual business activity over time to support economic research.
National Institute of Standards and Technology (NIST)
- NIST defines synthetic data generation as creating artificial datasets from seed data that retain statistical features.
- It lists synthetic data among recognized privacy-enhancing technologies and has published guidelines to evaluate data utility and disclosure risk.
U.S. Department of Health and Human Services (AHRQ)
- AHRQ developed the SyH-DR, a synthetic health database that mirrors claims data from Medicare, Medicaid, and private insurers.
- These synthetic datasets help simulate patient outcomes and service utilization for public health research without violating HIPAA.
European Innovative Health Initiative (IHI)
- The SYNTHIA and SEARCH projects under IHI are building synthetic datasets for clinical, genomic, and wearable device data across Europe.
- These efforts are designed to support longitudinal AI training models while maintaining patient anonymity.
U.S. Department of Homeland Security (DHS)
- DHS’s Synthetic Data Generator project supports creation of structured synthetic data for cybersecurity and AI training purposes.
- The datasets cover formats such as relational databases, tabular logs, and unstructured text using differential privacy mechanisms.
Maryland Longitudinal Data System (MLDS) Center
- MLDS is developing synthetic datasets representing education and workforce outcomes, allowing researchers to explore policy questions securely.
- These datasets simulate years of student data, performance metrics, and post-graduation employment trends.
U.S. Food and Drug Administration (FDA)
- The FDA supports synthetic data for use in clinical trial simulations and predictive modeling.
- It promotes the use of AI-ready synthetic datasets to enhance safety, efficiency, and reproducibility in medical device development.
National Science Foundation (NSF) / National Secure Data Service
- NSF funds programs exploring synthetic data to enable secure sharing of statistical and administrative datasets across U.S. agencies.
- These initiatives focus on making large data ecosystems interoperable and privacy-safe for research and AI innovation.
Global Synthetic Data Generation Market: Market Dynamics
Global Synthetic Data Generation Market: Driving Factors
Growing Demand for High-Quality AI Training Data
As AI and machine learning become deeply embedded in business operations, the need for large, diverse, and balanced training datasets has surged. Synthetic data addresses this demand by providing scalable, realistic datasets that help in model training without exposing sensitive information. Industries such as finance, healthcare, and autonomous mobility are leveraging synthetic datasets to improve algorithmic accuracy, reduce model bias, and cover rare or edge-case scenarios that are difficult to capture in real-world data. This growing reliance on synthetic AI training data is significantly driving market growth.
Increasing Focus on Data Privacy and Regulatory Compliance
Data privacy regulations like GDPR, HIPAA, and CCPA are limiting the use of real-world personal data for AI and analytics. Organizations are under immense pressure to anonymize or protect user data while still maintaining innovation in their AI pipelines. Synthetic data offers a privacy-preserving alternative that removes identifiable information while retaining the utility and structure of the original datasets. This helps companies avoid legal penalties, reduce compliance risks, and safely collaborate on data-sharing projects, further fueling market expansion.
Global Synthetic Data Generation Market: Restraints
Lack of Standardized Evaluation Metrics for Data Quality
One of the major challenges in synthetic data generation is the absence of universally accepted metrics to assess the quality, utility, and fairness of generated datasets. While real-world data can be measured against historical accuracy, synthetic data must balance realism with privacy preservation. Without standard benchmarks, organizations may face difficulties validating the effectiveness of synthetic datasets, leading to hesitancy in adoption. This limitation slows down deployment in highly regulated sectors like healthcare and defense.
High Computational Requirements and Technical Complexity
Generating high-fidelity synthetic datasets using advanced models such as GANs or diffusion algorithms often demands significant computational power, deep technical expertise, and infrastructure investments. Smaller enterprises and organizations with limited IT resources may find it challenging to implement these solutions effectively. Moreover, incorrect model configuration or data synthesis processes can lead to unrealistic or biased outputs, which can negatively impact AI performance.
Global Synthetic Data Generation Market: Opportunities
Integration with Real-Time Data Pipelines and Edge AI
As industries adopt real-time analytics and edge computing, there is a growing need for synthetic data that can be generated on-the-fly for continuous AI model training and validation. This presents a major opportunity for vendors to integrate synthetic data generation with real-time decision-making systems, particularly in sectors like IoT, robotics, synthetic data generation, and connected vehicles. These integrations will support faster iteration, reduce latency, and ensure consistent model updates without exposing live operational data.
Expansion in Emerging Economies and Data-Restricted Regions
Emerging markets across Asia-Pacific, Latin America, and the Middle East are experiencing rapid digital transformation but often lack access to high-quality structured data due to limited infrastructure or strict government restrictions. Synthetic data solutions offer these regions a powerful tool to accelerate AI development without violating data sovereignty laws. As governments and enterprises in these regions look to leapfrog into the AI economy, the demand for synthetic datasets is expected to grow exponentially.
Global Synthetic Data Generation Market: Trends
Rise of Multimodal Synthetic Data Platforms
Modern applications demand more than just one type of data, AI systems now require a combination of text, image, video, and tabular data to perform accurately. A rising trend in the synthetic data generation market is the development of multimodal platforms that can generate and synchronize various data types in a single ecosystem. These platforms are particularly valuable for complex AI models used in fields such as digital twins, medical diagnostics, and immersive virtual environments.
Increased Adoption in Cybersecurity and Simulation-Based Training
Organizations are beginning to use synthetic data to simulate cyberattacks, phishing threats, and other digital vulnerabilities to strengthen their cybersecurity defenses. Synthetic log data and threat scenarios help train intrusion detection systems and security personnel in controlled environments without exposing real network data. Similarly, synthetic data is being used in simulation-based training across sectors like defense, aviation, and emergency response, highlighting a shift toward risk-free, data-driven preparedness.
Global Synthetic Data Generation Market: Research Scope and Analysis
By Component Analysis
Software components are expected to dominate the synthetic data generation market by component segment, accounting for 67.0% of the total market share in 2025. This strong dominance is primarily driven by the growing demand for automated, scalable, and high-fidelity synthetic data generation platforms across industries. These software tools are designed to simulate complex datasets such as structured tabular data, medical records, image and video data, and time-series information.
Equipped with advanced machine learning algorithms including GANs and VAEs, synthetic data software enables businesses to generate customizable and realistic datasets that are essential for AI model training, testing, and validation. The growing integration of such platforms into cloud environments and their ability to support real-time data simulation make them indispensable for enterprises seeking to accelerate digital transformation while ensuring data privacy and compliance.
On the other hand, the services segment plays a critical role in enabling the successful adoption and optimization of synthetic data solutions. This includes a wide range of offerings such as consulting, implementation, integration, training, and ongoing technical support. Many organizations, particularly those in highly regulated or data-sensitive industries like healthcare and finance, rely on service providers to help them design and deploy secure synthetic data environments tailored to their specific business needs.
These services are especially valuable for enterprises that lack the internal expertise or infrastructure to manage synthetic data systems on their own. As synthetic data generation becomes more complex and use-case specific, the demand for specialized services is expected to grow, supporting long-term market expansion alongside the dominant software component.
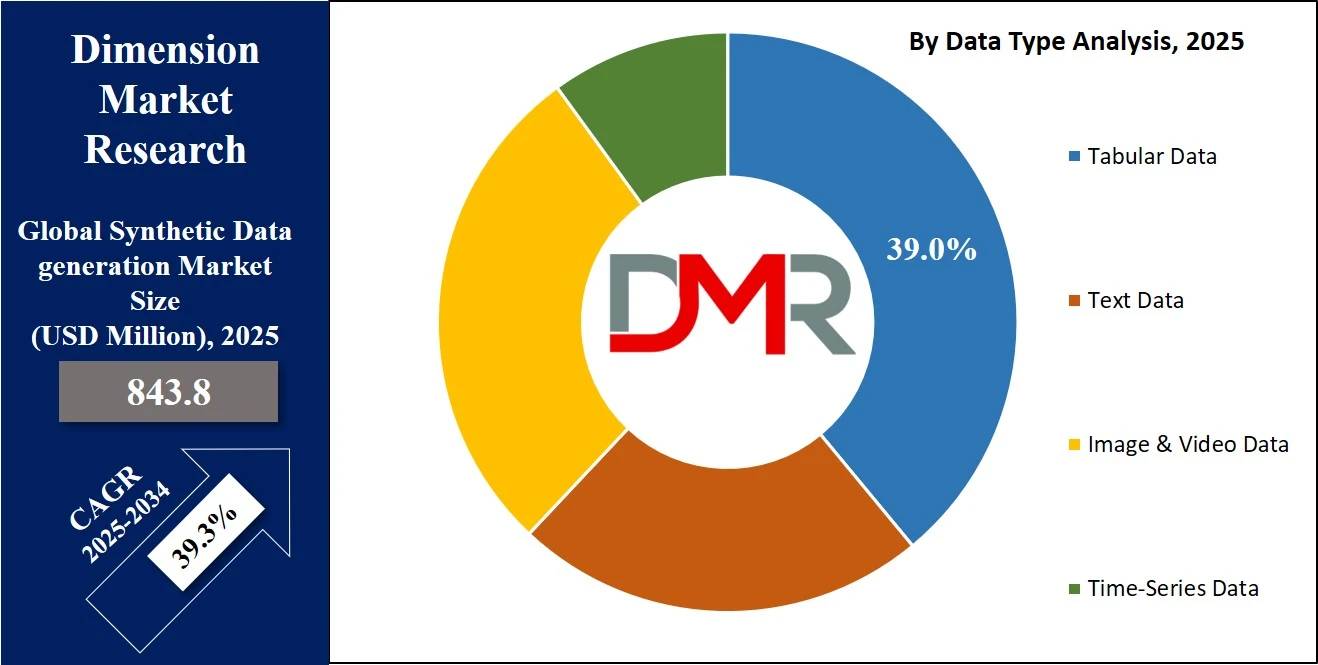
By Data Type Analysis
Tabular data is projected to remain the dominant data type within the synthetic data generation market, accounting for 39.0% of the total market share in 2025. This dominance is attributed to the widespread use of structured data across key industries such as finance, healthcare, retail, and insurance, where transactional records, customer profiles, clinical data, and operational metrics are central to business operations.
Synthetic tabular data allows organizations to create realistic yet anonymized datasets that mirror the patterns, relationships, and statistical distributions of original data without exposing sensitive or personally identifiable information. It plays a vital role in training machine learning models for applications like fraud detection, predictive analytics, customer segmentation, and regulatory reporting. The ability to generate diverse and balanced synthetic tabular data also helps organizations mitigate bias, handle data scarcity, and comply with privacy regulations such as GDPR and HIPAA.
In contrast, image and video data is emerging as one of the fastest-growing segments in the synthetic data landscape due to its growing application in computer vision, autonomous systems, and augmented reality. Industries like automotive, healthcare, retail, and security are leveraging synthetic image and video datasets to train AI models for object recognition, facial analysis, medical imaging diagnostics, and behavioral tracking.
Generative algorithms such as GANs and 3D rendering engines are used to create hyper-realistic visual data that can simulate a wide range of scenarios, lighting conditions, and object variations that may not be easily captured in real-world environments. This not only reduces the cost and time of manual data collection but also ensures that AI systems are better prepared for complex and edge-case conditions. As demand grows for advanced visual AI applications, the share of image and video data within the synthetic data market is expected to rise steadily.
ℹ
To learn more about this report –
Download Your Free Sample Report Here
By Model Type Analysis
Generative Adversarial Networks, or GANs, are expected to dominate the model type segment of the synthetic data generation market, holding 41.0% of the total market share in 2025. The primary reason for this strong position is the exceptional ability of GANs to produce high-quality, realistic synthetic data across various formats, including images, video, text, and structured datasets.
GANs work by training two neural networks, a generator and a discriminator, in a competitive framework, which leads to the creation of highly detailed and complex data samples that closely resemble real-world data. Their effectiveness in creating lifelike facial images, autonomous vehicle training scenarios, and simulated healthcare images has made GANs a go-to model for industries like automotive, healthcare, finance, and retail. The continuous advancements in GAN architecture and its flexibility across use cases further reinforce its leadership position in this segment.
Agent-based models, while capturing a smaller portion of the market, play an important role in specific applications that require behavioral simulation of individual entities or systems. These models simulate the actions and interactions of autonomous agents, such as humans, vehicles, or systems, in a given environment to assess outcomes at both micro and macro levels.
This modeling approach is particularly useful in sectors like urban planning, epidemiology, supply chain logistics, and disaster response, where understanding the emergent behavior of complex systems is crucial. Synthetic data generated from agent-based simulations enables organizations to evaluate different strategies, predict future scenarios, and test system responses without relying on historical or sensitive data. Although not as widely adopted as GANs, agent-based models are valued for their ability to generate contextual and dynamic synthetic datasets that are essential for real-world scenario planning.
By Deployment Mode Analysis
Cloud-based deployment is projected to consolidate its dominance in the synthetic data generation market, accounting for 71.0% of the total market share in 2025. This strong position is primarily due to the scalability, flexibility, and cost-efficiency that cloud platforms offer. Organizations across industries are adopting cloud-based synthetic data generation tools to support their AI and machine learning workflows, especially as data requirements grow in volume and complexity.
Cloud platforms allow for faster data synthesis, seamless integration with existing cloud-native AI systems, and real-time accessibility across geographically dispersed teams. Furthermore, cloud-based models are regularly updated with the latest generative algorithms, offer high-performance computing capabilities, and reduce the burden of maintaining on-site infrastructure. These benefits are particularly attractive to tech startups, mid-sized firms, and large enterprises looking to accelerate innovation while maintaining data security and compliance through cloud providers with robust security protocols.
On-premise deployment, while holding a smaller share of the market, remains an essential option for organizations that prioritize complete control over their data environments due to regulatory, security, or operational requirements. Industries such as healthcare, defense, and financial services often choose on-premise solutions to ensure data sovereignty, protect sensitive information, and maintain compliance with strict internal policies.
On-premise synthetic data systems offer greater customization, reduced third-party exposure, and uninterrupted access to internal resources. Although implementation and maintenance costs are generally higher than cloud-based options, the added control and privacy make on-premise deployment a preferred choice for high-security applications. This segment continues to serve a critical role in scenarios where cloud adoption is either restricted or strategically avoided.
By Organization Size Analysis
Large enterprises are expected to consolidate their dominance in the synthetic data generation market by organization size, capturing 66.0% of the total market share in 2025. This is largely driven by their substantial investments in artificial intelligence, machine learning infrastructure, and data-driven decision-making. Large organizations, especially in sectors like banking, healthcare, automotive, and technology, deal with vast and complex datasets that are often sensitive or regulated.
Synthetic data offers them a secure and scalable way to train and validate AI models without compromising on data privacy or regulatory compliance. These enterprises often have in-house data science teams, advanced R&D capabilities, and the resources needed to adopt sophisticated synthetic data platforms. Their usage extends from product development and customer analytics to risk modeling and simulation-based training, making them major contributors to market demand.
Small and medium-sized enterprises (SMEs), while representing a smaller portion of the market, are gradually growing their adoption of synthetic data solutions. With the democratization of AI tools and the rise of user-friendly, cloud-based synthetic data platforms, SMEs are finding new opportunities to enhance innovation without relying heavily on real-world datasets. These businesses often face challenges related to limited data availability, privacy concerns, and cost constraints.
Synthetic data enables them to overcome these hurdles by providing affordable access to realistic datasets that can power AI applications like customer segmentation, predictive analytics, and automation. Although their adoption rate is slower compared to large enterprises, SMEs represent a growing segment, particularly in industries such as retail, edtech, and digital services, where data agility and compliance are becoming important.
By Application Analysis
Data privacy and compliance applications are set to capture the largest share in the application segment of the synthetic data generation market, accounting for 28.0% of the total market value in 2025. The rise of global data protection regulations such as GDPR, HIPAA, and CCPA has compelled organizations to seek solutions that allow them to leverage data while safeguarding user privacy.
Synthetic data offers a powerful alternative to traditional anonymization techniques by generating entirely new datasets that retain the statistical properties of the original data without exposing any personally identifiable information. This approach is used in sectors like healthcare, finance, and government, where the use of sensitive data is tightly regulated. By enabling privacy-preserving analytics, cross-border data sharing, and regulatory compliance, synthetic data has become a key tool in ensuring data security without compromising on innovation or operational efficiency.
AI model training and testing is another significant application area within the synthetic data market, playing a crucial role in enhancing the performance, scalability, and fairness of machine learning systems. Real-world data often contains gaps, imbalances, or biases that can hinder model development and lead to poor generalization. Synthetic data helps overcome these challenges by generating balanced, diverse, and customizable datasets that can be tailored to specific use cases or edge-case scenarios.
This is particularly important in domains like autonomous driving, natural language processing, fraud detection, and robotics, where vast and varied datasets are essential for robust algorithm development. By supplementing or even replacing real data during the training and testing phases, synthetic data accelerates AI deployment while reducing dependency on sensitive or hard-to-acquire datasets, making it a vital enabler for scalable and ethical AI solutions.
By Industry Vertical Analysis
The BFSI sector is expected to consolidate its dominance in the industry vertical segment of the synthetic data generation market, capturing 22.0% of the total market share in 2025. This strong position is largely due to the financial industry's growing reliance on advanced analytics, artificial intelligence, and machine learning to detect fraud, assess credit risk, and enhance customer experiences.
Financial institutions handle vast volumes of highly sensitive data, and synthetic data provides a secure way to develop and test AI models without exposing real customer information. Applications include simulating fraudulent transaction patterns, improving algorithmic trading strategies, and developing risk models for lending and compliance. The need to comply with strict data privacy regulations such as GDPR, PCI-DSS, and regional financial oversight laws further pushes banks and insurance firms to adopt synthetic datasets for model training, testing, and regulatory reporting.
The healthcare and life sciences sector is another major contributor to the synthetic data generation market, driven by its ongoing digital transformation and the need to protect patient confidentiality. Hospitals, pharmaceutical companies, and medical researchers are using synthetic health records, diagnostic imaging data, and genomic information to build predictive models for disease detection, treatment optimization, and drug development.
Given the strict compliance requirements under regulations like HIPAA and the sensitivity of patient data, synthetic data allows stakeholders in the healthcare ecosystem to innovate safely without violating privacy laws. It also enables the modeling of rare conditions, supports data sharing across institutions, and improves algorithm accuracy by offering diverse, bias-reduced datasets. As personalized medicine and AI-driven diagnostics continue to evolve, the demand for high-quality, privacy-compliant synthetic medical data is expected to grow substantially.
The Synthetic Data Generation Market Report is segmented on the basis of the following:
By Component
By Data Type
- Tabular Data
- Image & Video Data
- Text Data
- Time-Series Data
By Model Type
- GANs (Generative Adversarial Networks)
- Agent-based Models
- Autoregressive Models
- Others
By Deployment Mode
By Organization Size
By Application
- Data Privacy & Compliance
- AI Model Training & Testing
- Fraud Detection
- Healthcare Diagnostics
- Autonomous Vehicles
- Others
By Industry Vertical
- BFSI
- Healthcare & Life Sciences
- IT & Telecom
- Retail & E-Commerce
- Automotive
- Government & Defense
- Manufacturing
- Others
Global Synthetic Data Generation Market: Regional Analysis
Region with the Largest Revenue Share
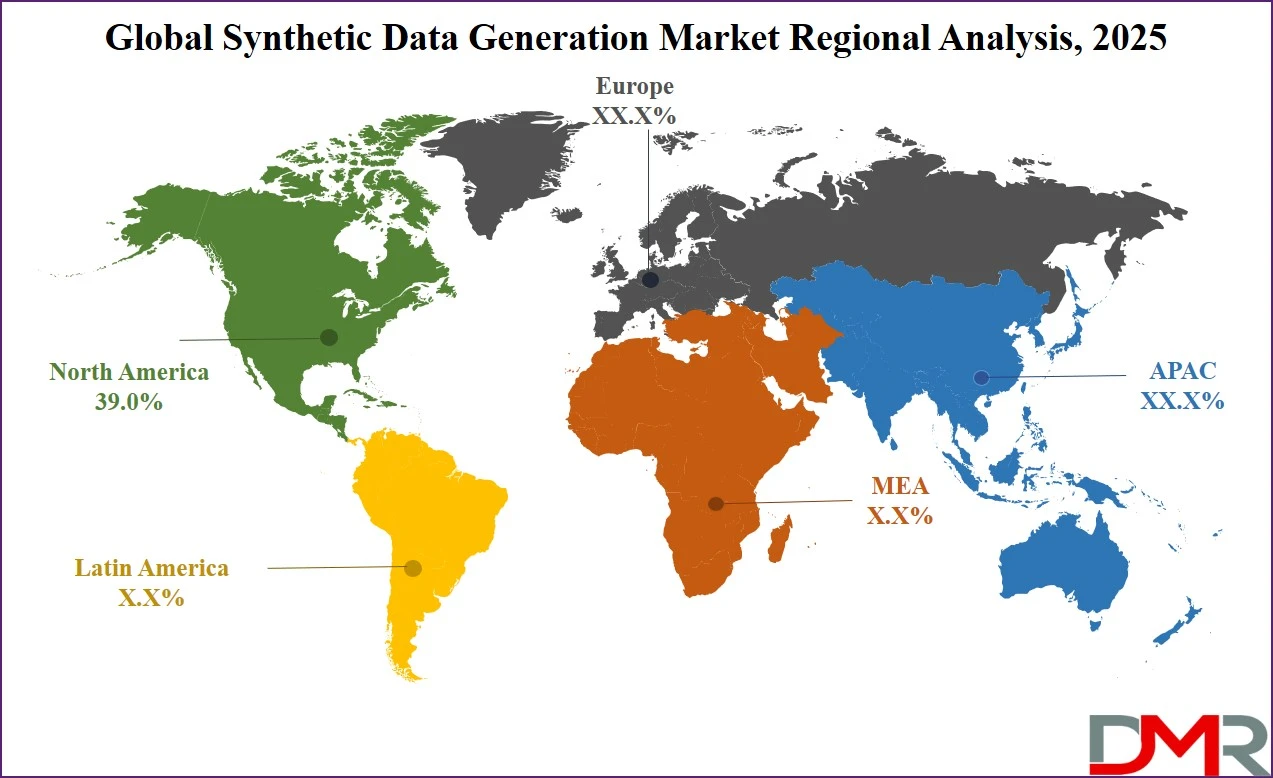
North America is anticipated to lead the global synthetic data generation market in 2025, accounting for 39.0% of the total market revenue. This leadership position is driven by the region’s strong technological infrastructure, early adoption of artificial intelligence across industries, and a high concentration of key market players, including major tech giants and innovative startups.
The United States, in particular, is at the forefront due to robust investments in AI research, growing data privacy concerns, and regulatory pressures that are accelerating the adoption of privacy-preserving data solutions. Sectors such as healthcare, finance, autonomous vehicles, and cybersecurity are leveraging synthetic data to improve model accuracy while maintaining compliance with regulations like HIPAA and CCPA. The region’s advanced cloud ecosystem and widespread use of machine learning further contribute to the strong demand for scalable and high-fidelity synthetic data platforms.
ℹ
To learn more about this report –
Download Your Free Sample Report Here
Region with significant growth
The Asia-Pacific region is projected to witness significant growth in the synthetic data generation market over the coming years, driven by rapid digital transformation, expanding AI adoption, and growing awareness of data privacy across emerging economies. Countries like China, India, Japan, and South Korea are investing heavily in artificial intelligence, smart city infrastructure, and autonomous technologies, all of which require vast and diverse datasets for model development.
However, strict data localization laws and limited access to quality training data have created a strong demand for synthetic alternatives. The region’s growing base of AI startups, government-backed innovation programs, and growing use of cloud-based platforms are further accelerating market expansion, positioning Asia-Pacific as a high-growth hub for synthetic data solutions.
By Region
North America
Europe
- Germany
- The U.K.
- France
- Italy
- Russia
- Spain
- Benelux
- Nordic
- Rest of Europe
Asia-Pacific
- China
- Japan
- South Korea
- India
- ANZ
- ASEAN
- Rest of Asia-Pacific
Latin America
- Brazil
- Mexico
- Argentina
- Colombia
- Rest of Latin America
Middle East & Africa
- Saudi Arabia
- UAE
- South Africa
- Israel
- Egypt
- Rest of MEA
Global Synthetic Data Generation Market: Competitive Landscape
The global competitive landscape of the synthetic data generation market is characterized by a dynamic mix of established technology giants and rapidly growing startups, each contributing to innovation and market expansion. Leading cloud service providers such as Microsoft, Amazon Web Services, Google, and IBM are integrating synthetic data capabilities into their AI and analytics platforms, offering scalable, and enterprise-grade solutions.
At the same time, specialized players like Mostly AI, Synthesis AI, Gretel.ai, Tonic.ai, and DataGen are disrupting the space with domain-specific offerings tailored to industries such as healthcare, automotive, and finance. The market is witnessing increased collaboration through partnerships, acquisitions, and open-source initiatives, as vendors aim to enhance synthetic data accuracy, support multimodal data types, and address privacy compliance challenges. With growing demand for AI-ready datasets, the competition is intensifying around innovation, data quality, and the ability to deliver flexible deployment models, positioning the market for continuous evolution.
Some of the prominent players in the global synthetic data generation market are:
- Mostly AI
- Synthesis AI
- Gretel.ai
- Hazy
- Tonic.ai
- YData
- DataGen
- Duality Technologies
- Syntegra
- MDClone
- Statice
- Delphix
- Parallel Domain
- Cognizant
- Accenture
- Microsoft
- IBM
- Amazon Web Services (AWS)
- Google (Alphabet)
- NVIDIA
- Other Key Players
Global Synthetic Data Generation Market: Recent Developments
- July 2025: Felt AI raised USD 15 million in Series A funding to advance its platform for AI‑driven geospatial mapping, focusing on environmental risk monitoring and natural-language-driven map creation.
- June 2025: SandboxAQ, an AI startup spun off from Google and backed by Nvidia, released a comprehensive synthetic dataset of approximately 5.2 million 3D molecular structures to accelerate drug discovery, enabling predictive modeling of drug–protein binding in early-stage research.
- June 2025: Ipsos unveiled a new AI-powered synthetic data offering for product testing, enabling faster simulation of consumer behavior and deeper insights, reportedly accelerating product launches by up to 50% and providing richer market intelligence.
- May 2025: Hugging Face acquired French robotics startup Pollen Robotics, marking a strategic merger between AI software and embodied systems development for next‑generation autonomous applications.
- March 2025: Nvidia reportedly acquired synthetic data startup Gretel in a deal exceeding USD 320 million, integrating its technology and team to enhance Nvidia’s AI training data ecosystem.
- April 2025: Nous Research secured USD 50 million in Series A funding led by Paradigm Operations, aiming to scale its decentralized AI training infrastructure to support next-gen model efficiency.
Report Details
| Report Characteristics |
| Market Size (2025) |
USD 843.8 Mn |
| Forecast Value (2034) |
USD 16,682.8 Mn |
| CAGR (2025–2034) |
39.3% |
| Historical Data |
2019 – 2024 |
| The US Market Size (2025) |
USD 276.8 Mn |
| Forecast Data |
2025 – 2033 |
| Base Year |
2024 |
| Estimate Year |
2025 |
| Report Coverage |
Market Revenue Estimation, Market Dynamics, Competitive Landscape, Growth Factors, etc. |
| Segments Covered |
By Component (Software and Services), By Data Type (Tabular Data, Image & Video Data, Text Data, and Time-Series Data), By Model Type (GANs, Agent-based Models, Autoregressive Models, and Others), By Deployment Mode (Cloud-Based and On-Premise), By Organization Size (Large Enterprises and SMEs), By Application (Data Privacy & Compliance, AI Model Training & Testing, Fraud Detection, Healthcare Diagnostics, Autonomous Vehicles, and Others), and By Industry Vertical (BFSI, Healthcare & Life Sciences, IT & Telecom, Retail & E-Commerce, Automotive, Government & Defense, Manufacturing, and Others). |
| Regional Coverage |
North America – US, Canada; Europe – Germany, UK, France, Russia, Spain, Italy, Benelux, Nordic, Rest of Europe; Asia-Pacific – China, Japan, South Korea, India, ANZ, ASEAN, Rest of APAC; Latin America – Brazil, Mexico, Argentina, Colombia, Rest of Latin America; Middle East & Africa – Saudi Arabia, UAE, South Africa, Turkey, Egypt, Israel, Rest of MEA |
| Prominent Players |
Mostly AI, Synthesis AI, Gretel.ai, Hazy, Tonic.ai, YData, DataGen, Duality Technologies, Syntegra, MDClone, Statice, Delphix, Parallel Domain, Cognizant, Accenture, Microsoft, and Others. |
| Purchase Options |
We have three licenses to opt for: Single User License (Limited to 1 user), Multi-User License (Up to 5 Users), and Corporate Use License (Unlimited User) along with free report customization equivalent to 0 analyst working days, 3 analysts working days, and 5 analysts working days respectively. |
Frequently Asked Questions
How big is the global synthetic data generation market?
▾ The global synthetic data generation market size is estimated to have a value of USD 843.8 million in 2025 and is expected to reach USD 16,682 million by the end of 2034.
What is the size of the US synthetic data generation market?
▾ The US synthetic data generation market is projected to be valued at USD 276.8 million in 2025. It is expected to witness subsequent growth in the upcoming period as it holds USD 4,638.5 million in 2034 at a CAGR of 36.8%.
Which region accounted for the largest global synthetic data generation market?
▾ North America is expected to have the largest market share in the global synthetic data generation market, with a share of about 39.0% in 2025.
Who are the key players in the global synthetic data generation market?
▾ Some of the major key players in the global synthetic data generation market are Mostly AI, Synthesis AI, Gretel.ai, Hazy, Tonic.ai, YData, DataGen, Duality Technologies, Syntegra, MDClone, Statice, Delphix, Parallel Domain, Cognizant, Accenture, Microsoft, and Others.
What is the growth rate of the global synthetic data generation market?
▾ The market is growing at a CAGR of 39.3 percent over the forecasted period.